
Summary
This evaluation compares the performance of Consensus and Google Scholar on the core task of a literature review: finding relevant papers. Using 500 real user queries and ~10,000 query–paper pairs, we evaluated top-10 results from each system with LLM-based relevance scoring (0–4 scale), blinded to source. Consensus outperformed Google Scholar across all key search relevance metrics: achieving 4.6% higher average precision and stronger DCG scores, meaning it not only finds more relevant papers but also ranks them with more precision. The advantage across metrics is most pronounced in the top five results, where researchers spend most of their time. For researchers, students, and professionals, this means less time sifting and more time learning, proof that smarter academic search is not only possible, and it’s already here.
1. Introduction: Why This Evaluation?
Google Scholar is the gold standard in academic search. While new AI tools (including Consensus) have gained traction in recent years, Google Scholar still dwarfs the rest of us in traffic and usage. Despite its clunky interface, Scholar is still widely considered the most reliable way to find relevant research, quickly.
At Consensus, we’re transparent about our ambition: we want to become the default starting point for literature search. To get there, we need to be better than Google Scholar. This evaluation was designed to answer a simple question: how do we compare on the core task of a literature review—finding relevant papers?
2. Methodology
We compared Consensus (using our Quick search mode) against Google Scholar. Importantly, we did not test our Deep Agentic mode or our Pro Search mode, which can both run iterative, multi-query searches, something a “classic” search engine like Google Scholar doesn’t do.
To keep things apples-to-apples, we only tested the core single-query search function of each product.
- Queries: 500 randomly sampled queries from actual Consensus users (anonymized and scrubbed for all PII) . These ranged from simple keywords, to metadata queries, to natural language questions.
- Results: For each query, we pulled the top 10 results from both Consensus and Google Scholar, creating ~10,000 (query, paper) pairs.
- Relevance Judging: We relied on the title + abstract for evaluation (due to access restrictions). Each query/paper pair was scored on a 0–4 scale (0 = irrelevant, 4 = perfectly relevant) by GPT-4o, GPT-o1, and GPT-o3, using the same prompt across models.
- Important note: Scores reflect textual relevance only—not recency, citation count, or journal quality (e.g. a perfectly aligned but obscure 1985 paper could still receive a 4).
- Bias control: The models were not told which product each result came from and used the same prompts across models. Prompts were constructed using industry best practices for “LLM-as-a-judge” label generation.
3. Results
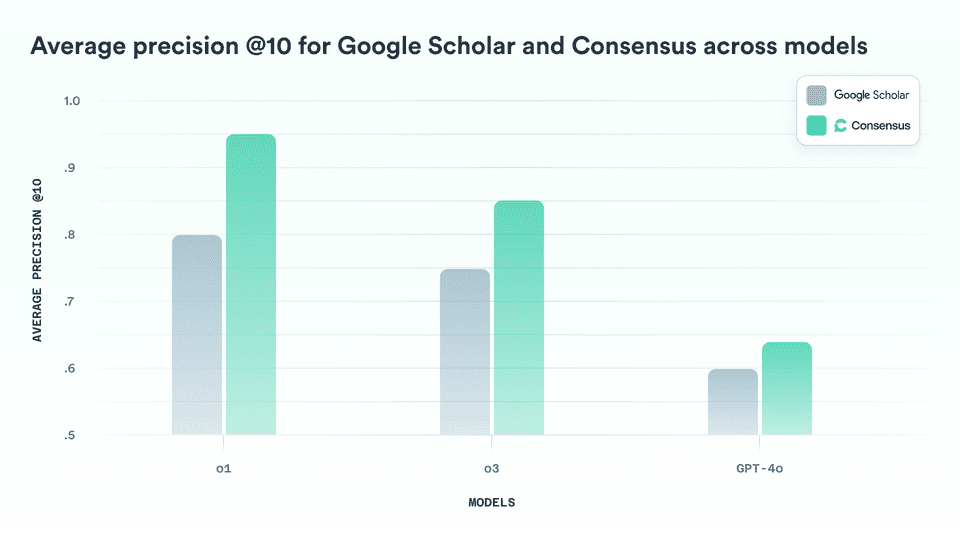
3.1 Average Precision
Average precision measures the total % of results that were scored as a 3 or 4 (a paper that is overall relevant to the user query). This metric is a good overall measure of how each product does at returning relevant results across user queries.
Across all three evaluation models, Consensus outperformed Google Scholar. Consensus achieved an average precision of 75.1%, compared to 71.8% for Google Scholar. Overall, Consensus was 4.6% better (3.3% net points) at returning relevant papers than Google Scholar.
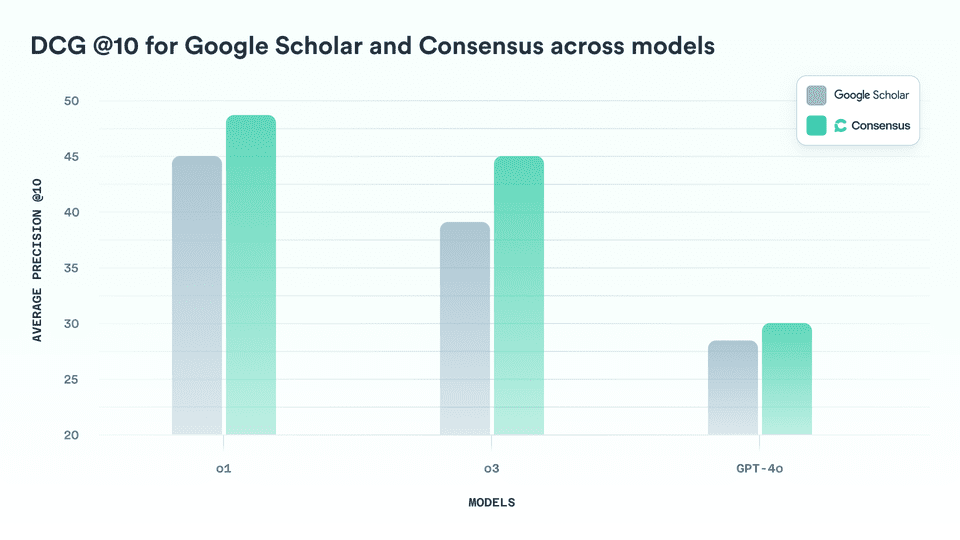
3.2 DCG
Discounted Cumulative Gain (DCG) is a relevance measure of ranking quality that weights higher-ranked results more heavily than lower-ranked ones. In practice, this means that retrieving a relevant paper (score 3 or 4) in the top 5 positions counts more than finding one near the bottom of the list.
Across all three evaluation models, Consensus again outperformed Google Scholar. Consensus achieved an average DCG of 39.68, compared to 37.54 for Google Scholar. Overall, Consensus was better at placing relevant papers higher in the rankings.
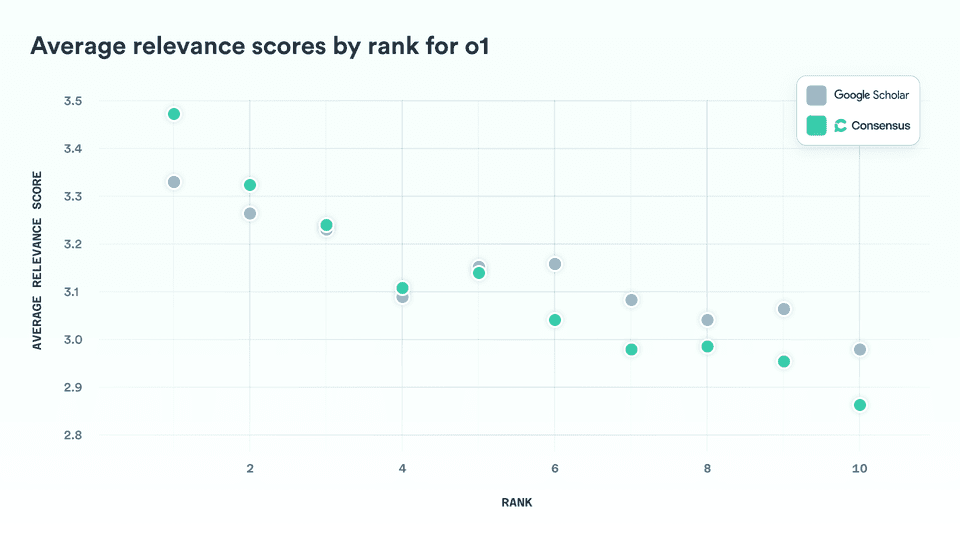
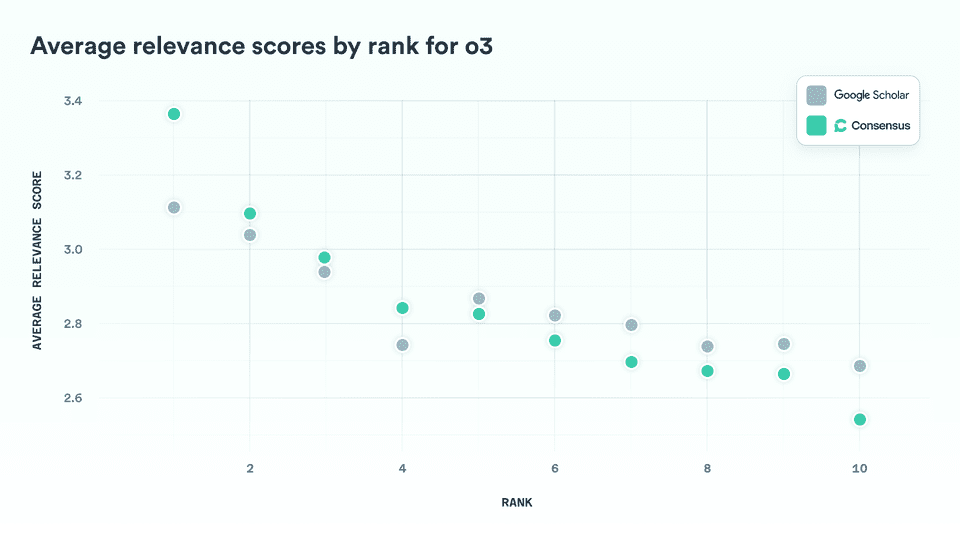
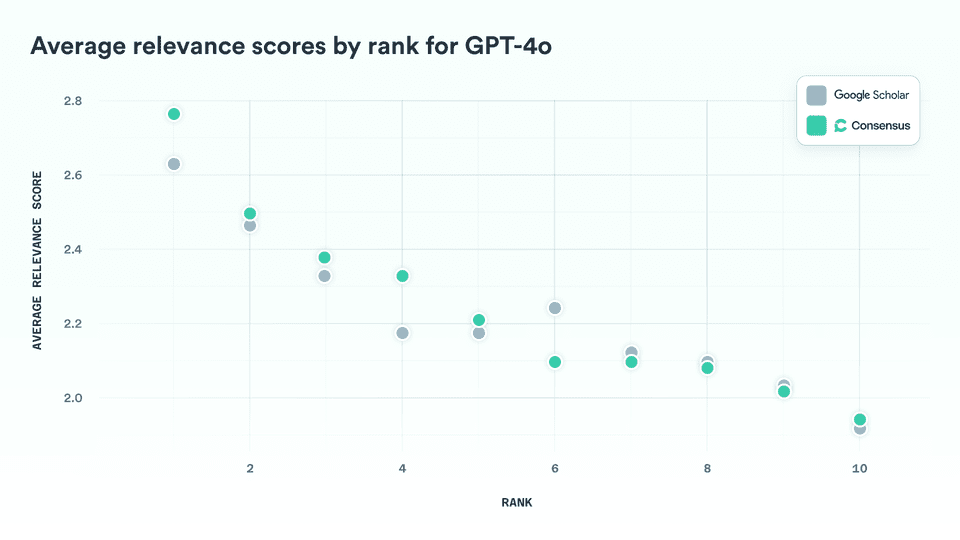
3.3 Average Relevance by Rank
To compare how each system performs at different positions in the results list, we calculated the average relevance score at each rank across all queries.
The pattern is consistent: Consensus delivers higher average relevance in the top four results, while Google Scholar performs slightly better in positions six through ten. As expected, both systems—and all models—show a steady decline in relevance as rank increases, reinforcing the validity of the evaluation.
Google Scholar’s edge at lower ranks (positions 6–10) likely reflects its superior corpus coverage and the resources to run larger ranking models across more documents. Expanding coverage, and running our smartest models over more papers are area we’re actively investing in at Consensus.
The more important, and encouraging, finding is that Consensus outperforms Google Scholar in the top five results. We attribute this to the strength of our AI-driven ranking systems, which we believe set a new standard for relevance. While Google Scholar benefits from unmatched coverage, our results suggest that when it comes to ranking intelligence, Consensus is ahead.
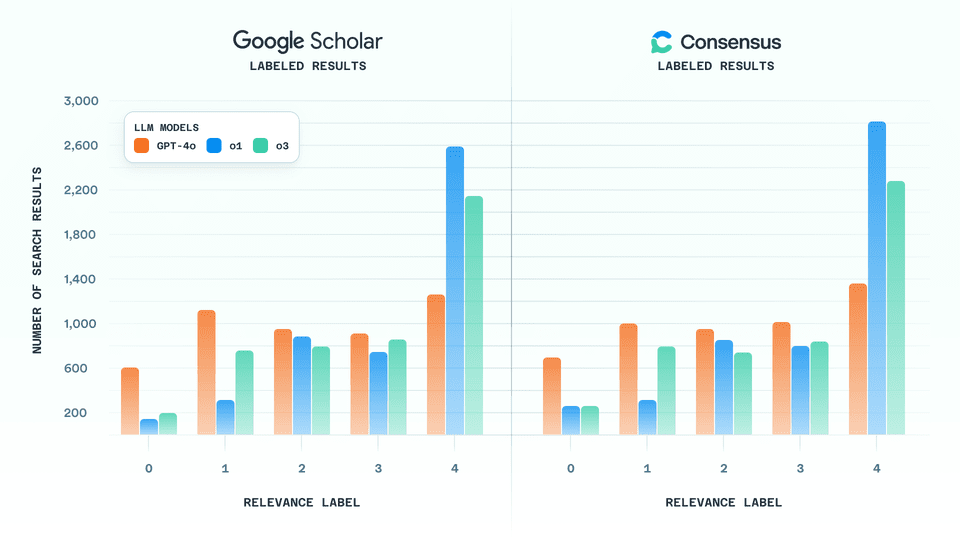
3.4 Model scoring distribution
GPT-4o, o1 and o3 were used to label each search result from both Consensus and Google Scholar for all queries. Among the models, GPT-o1 was the most lenient while GPT-4o was the strictest. For instance, GPT-o1 assigned roughly twice as many top scores (4s) compared to GPT-4o.
4. Conclusion and Discussion
This evaluation demonstrates that Consensus not only matches Google Scholar but consistently outperforms it across nearly every measure of search relevance, with an overall advantage of 3–4%. The gap is most pronounced in the highest-ranked results, the positions that matter most, since researchers spend the bulk of their time on the first page. Here, Consensus reliably delivers more relevant papers than Google Scholar.
Scholar continues to benefit from advantages like unparalleled paper coverage, which helps partially explain its marginal advantage in lower-ranked results. However, the strength of Consensus lies in its AI-driven ranking systems, which consistently surface the most useful material at the top of the list. For researchers, students, and academics, this means faster, more efficient access to the work that matters most.
The findings reinforce a broader point: scale and familiarity are no longer the only determinants of search quality. By pushing ranking intelligence forward, Consensus proves that smarter, more precise discovery is both possible and impactful, and that there is real room to improve how we navigate the scientific literature.