
What is Consensus?
Consensus is an AI search engine for academic research. It searches over 200 million academic papers and uses language models to help find, understand, and synthesize peer-reviewed literature.
For every query, Consensus first retrieves the most relevant academic papers. Then, our AI analyzes the top results and generates a clear, cohesive synthesis of the findings. Every response includes citations, so you can trace each insight back to the original source.
Consensus is built to find and review literature more efficiently, while still ensuring proper source attribution. We are used today by over 5 million students, researchers and faculty members from over 10,000 different universities.
How Consensus Works With Libraries?
Consensus is available for both individual users and institutions. We partner with university libraries of all sizes and locations to provide broad access to our platform. Most libraries choose to acquire a sitewide license, enabling all enrolled students and faculty to use Consensus without requiring individual subscriptions.
How Consensus Delivers Access to Students?
When a sitewide license is activated, Consensus automatically authorizes all associated university email domains. Any university-affiliated user who signs up (or has already signed up) with an authorized email address will be added to the institutional license and granted full access to the platform.
All that is needed from end users is to create an account with their university email address and a password. We’ve seen strong success with this authentication method with our library partners.
Consensus Library Pricing
We’re excited to announce that we’re offering free, unlimited access to Consensus for the entire 2025–26 academic year to any university library. This is more than a promotion, it’s our commitment to partnering with the academic community to explore how AI can be used responsibly to improve learning and research outcomes.
We want to collaborate with you in shaping the future of AI in academia, and we believe the best way to start is by removing financial barriers.
How Consensus Fosters Ongoing Collaborations with Libraries
We’re offering a full year of free access because we want to build Consensus with university libraries, not just for them. As a two-year-old startup, our product is evolving quickly, and we deeply value input from academic partners to shape what comes next.
To create an environment conducive to continuous feedback, academic partners get:
- Always-on communication via email or Slack
- Quarterly feedback sessions with our founding team
- Influence on features, functionality, and roadmap direction
Your feedback won’t sit in a form, it will help shape the future of how AI supports academic research. Further, to assist in your evaluation of Consensus, we provide partners with detailed quarterly usage reports, including metrics like: accounts created, searches per user, papers clicked, and papers saved.
Consensus Product Information:
What Does Consensus Search Over?
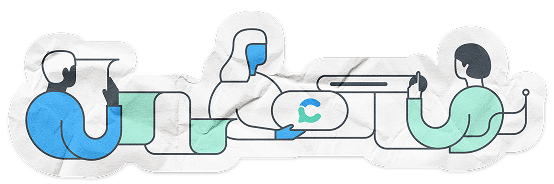
Our corpus includes over 200 million academic documents across all domains of science —primarily peer-reviewed journal articles, along with some conference papers and preprints.
We’ve built this corpus by aggregating data from three major sources:
- Semantic Scholar
- OpenAlex
- Our own crawl of the scholarly web to fill in important coverage gaps
By combining these sources, Consensus covers nearly all of the highest-impact journals and the entirety of PubMed. Think of Consensus as an AI-native alternative to Google Scholar with a more-refined corpus.
How Consensus Works and How to Best Search?
These topics are hard to cover in a few sentences! We have written a blog going into this in depth. If you want to learn further, we encourage you to read this piece:
How Consensus Handles Access to Full-Text Articles
We want to be upfront about what Consensus is and is not. Consensus does not provide special access to paywalled journal articles. Instead, we operate as a powerful discovery and analysis layer on top of the academic literature.
Here’s how that works:
- For Open Access papers, users can directly download the full-text PDF through Consensus.
- For paywalled articles, we provide a direct link to the publisher’s page along with rich metadata and abstracts to help users determine relevance, without violating any copyright laws
We’re excited to share that starting in the 2025–26 academic year, Consensus will integrate with LibKey. This means any user under your university’s site license will be able to see exactly which paywalled articles are accessible through your institution’s library subscriptions.
Consensus is designed to complement and amplify your library’s holdings, not replace them.
How Consensus Uses AI Responsibility
At Consensus, we’re committed to using AI ethically, transparently, and with purpose. Always in service of helping researchers, students, and educators save time without sacrificing trust or accuracy.
The simplest way to understand our approach is this: We only use AI after we search the scientific literature. This ensures that every response is grounded in real, citable research, not speculative content generated by a model.
Once relevant papers are retrieved, we use AI in two key ways:
- To analyze individual papers in depth (e.g. Ask Paper, Study Snapshot)
- To synthesize findings across multiple papers (e.g.Pro Analysis, Consensus Meter)
We use two types of AI models in these AI features:
- Commercial models (like OpenAI) for general-purpose summarization
- Fine-tuned open-source models for domain-specific features, like the Consensus Meter
Regardless of the model or use-case, we never use user data to train systems, and we never share your data with third parties. Your data stays private and stays yours.
Specific Guardrails Against AI Misuse
Generative AI is a powerful tool that can win us back critical time to focus on what matters most, but it must be used carefully to ensure positive outcomes. At Consensus, we’ve built in safeguards to reduce the risk of AI misuse:
- Search before synthesis: Every response starts with a literature search. This ensures all citations are real papers, never hallucinated or invented sources.
- Summarization, not speculation: Our AI tools are strictly limited to summarizing content from the papers retrieved. They don’t “fill in the blanks” with outside knowledge.
- Transparent sourcing and attribution: Every claim is cited, and every citation is clickable. We make it incredibly easy in our UX to inspect, verify, and reference the original source content with one click.
- AI “checkers” for relevance: Before summarizing, we use separate models to verify that the source actually contains information relevant to the query. If a paper doesn’t meet our threshold for relevance, it won’t be used in the response. Think of this as a measure to make sure that we “set our models up for success”.
Consensus is built to enhance—not replace—the research process. Our goal is to provide a faster path to high-quality evidence, while always keeping humans in control.
How Consensus Deals With Hallucinations:
Let’s talk about “hallucinations.” Hallucinations are a common issue in AI systems where models generate something that is not true. These usually fall into three categories:
- Fake sources – the AI cites a paper or article that doesn’t exist.
- Wrong facts – the AI generates a confident answer from internal memory that’s simply incorrect with no source.
- Misread sources – the AI summarizes a real paper or source, cites it, but gets it wrong.
Thanks to how we’ve built Consensus, only the third type of hallucination is possible, and we work hard to minimize it.
Consensus isn’t a chatbot. It’s a search engine that uses AI to summarize real scientific papers. Every time you ask a question, we search a database of peer-reviewed research. That means:
- Every paper we cite is guaranteed to be real
- Every summary is based on actual research, not a model’s guess or internal memory
Still, no AI system is perfect. Sometimes a model can misinterpret a paper and summarize it incorrectly and this can happen in Consensus. To reduce this risk, we’ve added safeguards like “checker models” that verify a paper’s relevance before summarizing it.
Most importantly, we’ve designed the product to make it easy for you to dive into the source material yourself. The best use of Consensus isn’t just getting a quick summary, it’s using our tools to explore the research in depth. That’s when real understanding happens.
Data Security
At Consensus, data privacy and responsible AI usage are foundational to how we operate. As we emphasized in our section on responsible AI practices: your data is never used to train any AI models—neither ours, nor those of any third party.
We understand that trust is critical, especially in academic and library settings. That’s why Consensus never collects or stores personally identifiable information (PII). We do not track individual users or tie usage to identities. Instead, we only collect anonymized usage data to help us improve the product.
We don’t sell data, partner with advertisers, or engage in any third-party data sharing. Your activity on Consensus stays private, and stays with us.