Introducing: The Consensus Meter
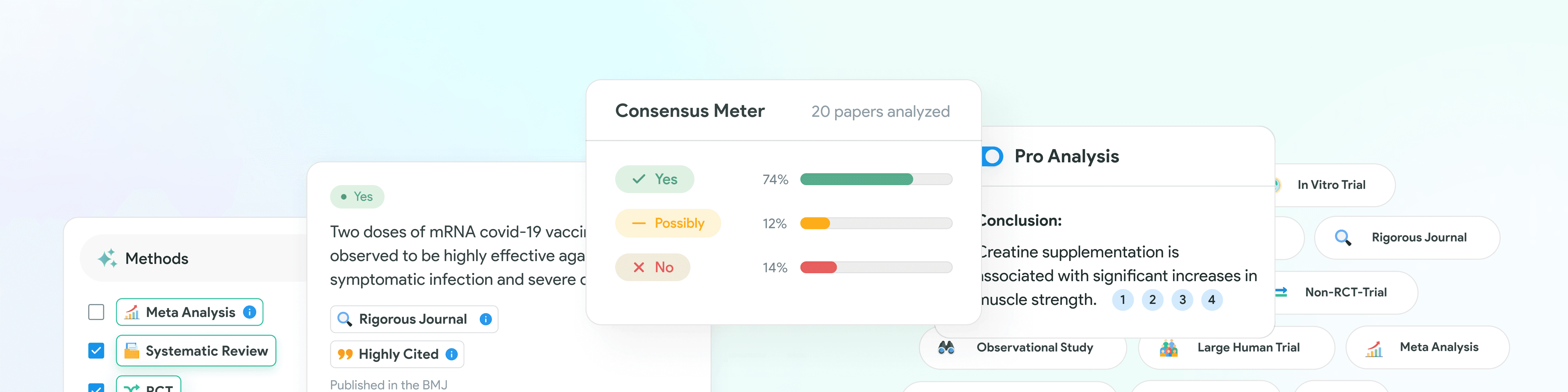
Consensus Meter, see the direction of scientific consensus
Scientific consensus is difficult. Answers in science are rarely black and white, each new research paper builds on all the research that came before it. One source says ‘yes’, the other ‘no’. It can take hours to sift through many studies, figure out which direction their answer goes, and get an idea of the overarching scientific consensus. Enter the Consensus Meter.
Paper classifications
For "Yes/No" questions, the Consensus Meter uses large language models to instantly classify the results as indicating "yes", "no" or "possibly" in a clean, aggregated interface. The meter will run over the first 20 results and will only classify answers that our model believes are relevant enough to your question. Our vision for Consensus is to deliver users rigorous, evidence-based insights at the click of a button. The Consensus Meter is the next step toward our vision.
Note: The Consensus Meter has limitations to recognize. Please see the sections below for details: Limitations, Guardrails.
The Consensus Meter in action
To see it in action, try asking a yes/no question like:
☀️ Does morning sunlight improve mood?
🛌 Does a lack of sleep increase Alzheimer's risk?
🚶 Does THC effect coordination?
👥 Does intergroup contact reduce prejudice?
💇♀️ Do some hair dyes increase risk of cancer?
💍 Do married people live longer?
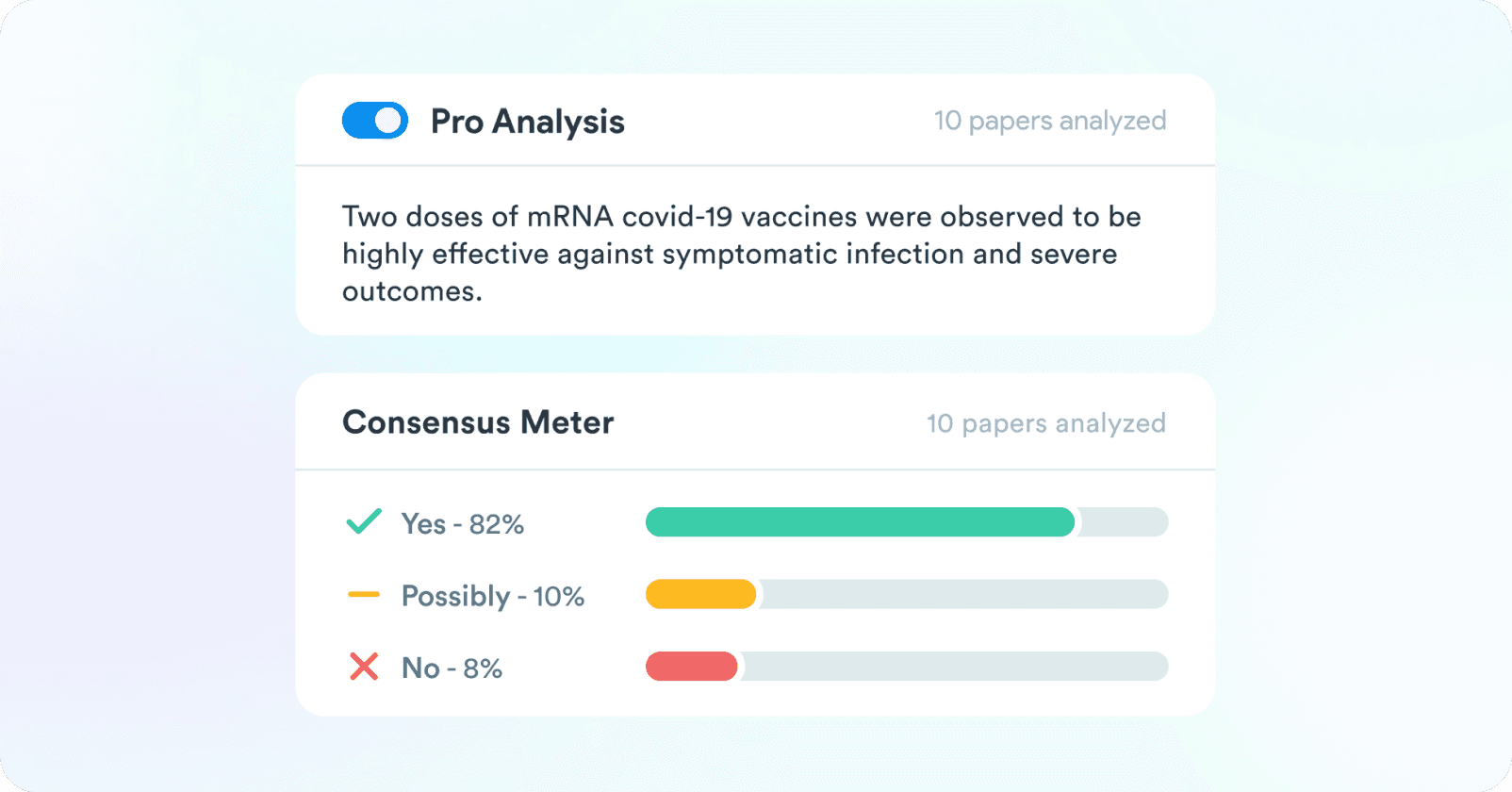
The Future of AI-Powered Search
With the release of ChatGPT, the world came around to the fact that language models are going to fundamentally change the way we consume and search for information. Fewer ads and blue links, more answers. We agree. However - not only should we have beautiful "answer engines" like ChatGPT and all its future iterations, but we also need "synthesis engines" that conduct automated analysis, aggregating answers across many sources at scale.
Synthesis engines are especially needed in domains where deeper analysis is warranted - like science. Think of the Consensus Meter as an AI-powered scientist that sifts through the top 20 most relevant papers about your question and tells you what they say.
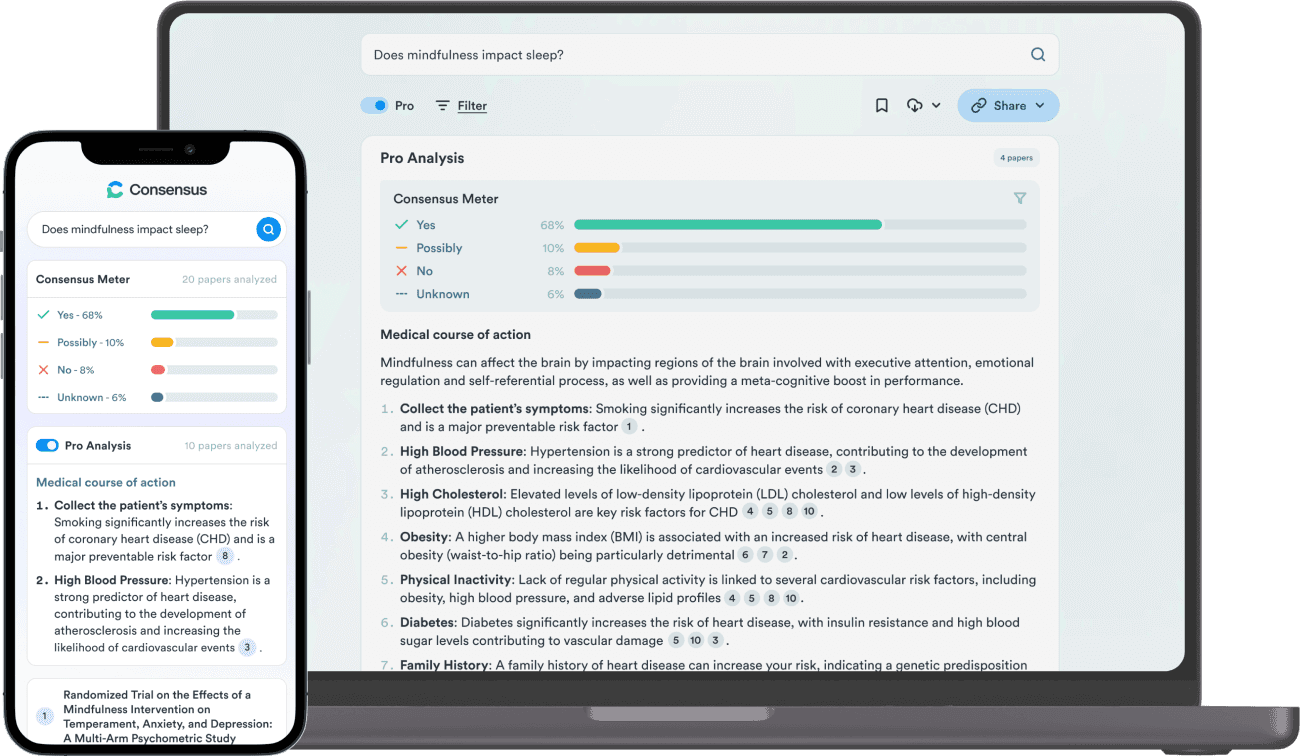
Guardrails
We are as excited as anybody about the future of AI-powered information. However, we also want to ensure that the powerful features we release are built thoughtfully, ethically, and with guardrails in place to further assist in delivering good information.
Here are a few ways that we are trying to put guardrails on the Consensus Meter:
No black boxes - all the results that power the Consensus Meter can be seen directly below its interface with corresponding tags indicating how they were classified. Our model is far from perfect, and we want to give users full transparency into what results power the meter.
Our results are extracted, not generated - most LLM-powered products are generative, meaning the AI is actually creating text. Unfortunately, these models sometimes outright hallucinate. To help mitigate this, the results that power the Consensus Meter are all extracted word-for-word quotes from papers.
Relevancy and confidence thresholding - if our models do not think the results are relevant enough to answer your question, we will exclude them from our analysis. Additionally, if our classifier model is not confident enough in what direction an answer leans, we won't force a prediction and will also exclude it from our analysis.
Limitations
But - there are still plenty of limitations, and this feature (and all other features) will continually be improved over time.
A few limitations to call out:
The model will incorrectly classify results - we have worked hard to give our model loads and loads of examples to learn from, but it is not infallible. By our calculations, our model will incorrectly classify results 10% of the time. This is more likely for confusing results like claims that are written with a double-negative, or other convoluting language.
Specific nuance is missing - one of the biggest limitations–that we are currently working to address–is that this feature does not always account for details included in the original question. For instance, if you ask, "Is ibuprofen safe for adult consumption?" and the potential result reads, "We found that ibuprofen was safe and well tolerated in children," our model may classify that result as "Yes."
Research quality is not a part of the analysis - another limitation that we cannot wait to address! Currently, each claim counts the same on the roll-up interface regardless if it comes from a meta-analysis or an n = 1 case report. Not all research is created equal and future versions of this feature will take into account both paper and journal quality. Remember, sometimes the most relevant answers come from junk research.
We do not have access to all research - the Consensus database includes north of 150 million peer-reviewed papers. While this represents significant coverage, there is plenty of amazing research that we do have access to. The meter is just a snapshot of some of the relevant research that we have access to, not a fully-comprehensive look into all of the research regarding your question.
Feedback
The Consensus Meter is in Beta, and we need your help to improve it! If you see any answers misclassified, please let us know by either:
Opening a support ticket in the chat widget
Or sending an email to [email protected]
Please include the following 2 pieces of information in your feedback:
The link to your query (ex: https://consensus.app/results/?q=Can%20Zinc%20help%20treat%20depression%3F&meter=on)
What was incorrect? (ex: The 3rd answer, "Results show zinc is effective…" should be classified as 'Yes'.)
Start searching for free in Consensus!
Consensus searches through 220M+ peer reviewed research papers and provides you the best insights from them. Helping you find better papers, faster.

Sign Up
